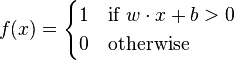Three easy ways to avoid off-by-one errors in your software

Here's how to avoid one of the commonest software bugs If you're in the software business you've probably encountered the dreaded 'off-by-one' error. An off-by-one error often occurs when an iterative loop iterates one time too many or too few. Someone might use "is less than or equal to" where "is less than" should have been used. It's also easy to forget that a sequence starts at zero rather than one. To put it another way, we sometimes fail to distinguish between a count (how many are there?) and an offset (how far is that from here?) Ten gaps in eleven posts These problems aren't unique to programming. At the time of the last millennium, there was a lot of discussion as to whether it should have been celebrated on 1st January 2000 or 2001. In debates about the millennium off-by-one errors may not be too serious. In software they can be fatal. How can you avoid them? Here are three techniques which help. I'll ...