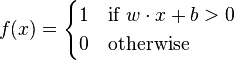Neural networks on the Raspberry Pi: Sigmoid, tanh and RL neurons

A brief introduction to ANNs - part 3 In the previous post about ANNs we looked at the linear neuron and the perceptron. Perceptrons have been used in neural networks for decades, but they are not the only type of neuron in use today. When they were first invented, they seemed capable of learning almost anything. However, in 1969, Minsky and Papert published their book 'Perceptrons' which showed that a single perceptron could never be trained to perform the XOR function. You'll see in the next post why this is so (and why it's not a huge problem), but for now, let's look at three other common neuron models. Like the linear neuron and perceptron, these start by calculating the weighted sum of their inputs. Recall that you can implement the linear neuron like this: ln←{⍺+.×⍵} sigmoid neuron calculates the same weighted sum of inputs, but then it applies the sigmoid function to the result. The sigmoid function is defined in wikipedia